|
|
|
|
| VBspeed / Articles / TextCompare Light |
| VBspeed © 2000-10, updated: 27-May-2002 |
| TextCompare Light |
|
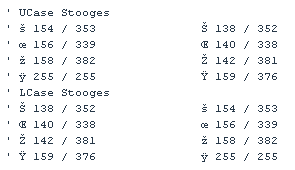
Text, Orthography, Unicode. Since we got Unicode, we got problems. Or rather, we got many more solutions than we had problems, and that can be a problem. Whereas a string is just a simple row of bytes, text means coping with orthography, which is a wild beast of history and culture shaped by the irregularities of human language evolution. We have to face this beast whenever we are comparing strings in the TextCompare mode, and when changing Case (UCase/LCase). In the early ASCII-days (7-bit set) we had 2 times 26 letter chars and changing case meant adding or subtracting 32. Then ASCII/ANSI (8-bit set) introduced french, spanish and other non-english european letters, plus a bunch of signs and symbols, and things became less trivial. The days of inline-solutions were definitely over. With Unicode, the digital concept of orthography left the tiny circle of Central-European languages. Unicode's 65536 theoretical letters are claimed to cover all writing systems found on the planet (which is wrong, of course, but the ones not featured certainly don't have the money to complain). Whatever, the point is: Unicode covers more languages than you know how to write in. Now, to do the TextCompare job right, you have to know at least the following (and that's for all languages covered in Unicode!): 1. Case equivalence: "s"="S", "đ"="Đ", etc. ... 2. Digraphemic equivalence: "ß"="ss", "ć"="ae", etc. ... 3. Sort order, and Sort order equivalence: "ü">"ö", "ü"="ue", "1"="ą", etc. ... And there are probably other much stranger phenomena in non-european languages. Visual Basic: TextCompare Heavy. VB native functions like InStr, InStrRev, Replace, StrComp know the TextCompare mode and they know how to do it right for all the 65536 Unicode chars. Also LCase and UCase know how to change case for all those languages (by the way, i counted only 408 cases of case conversion, but the number will probably rise in future editions). So, Visual Basic provides smart functions that follow the rules and work correctly regardless of the language. Alas, with computers (and brains...), smart means slow. If you are a eurocentric ANSI kind of guy, the globalized unicode power is wasted on you. What you need is something dumb and fast! VBspeed: TextCompare Light. VBspeed features a number of functions that know the TextCompare mode: for example Compress, InStrCount, InStrRev, IsSameText, Replace. Here, TextCompare is defined as follows: ***************************************************************************** The rules for VBspeed's TextCompare Light: ============================================================================= 1. We ignore all the digraphemic stuff! So for us "ss" <> "ß" in *any* mode! 2. Neither shall we waste our precious time with upper Unicode textual comparison. We care for ANSI chars only. 3. We must, however, care for the 4 ANSI stooges: š/Š, ś/Ś, ž/Ž, ˙/ź. See below The Stooges. => if you think "to hell with the stooges" i'll tell Iggy Pop! 4. Just to complicate things, the following pairs are viewed as equal by VB6, but not by VB5 (we go with VB5): VB6: 1(49)=ą(185), 2(50)=˛(178), 3(51)=ł(179) VB5/VBspeed: 1(49)<>ą(185), 2(50)<>˛(178), 3(51)<>ł(179) ***************************************************************************** The Stooges. A bunch of upper ANSI chars is handled by VB in a surprising manner (but see the comment by Arsen below!). For example, Chr$(154) returns "š". Now when you ask for Asc("š") you get 154, so far so good. But AscW("š") gives you 353: no zero in the upper unicode half! So VB internally translated 154 (hex 00 9A) into 353 (hex 01 61). You have to know this if you want to emulate ANSI UCase/LCase. Here is a list of ANSI chars with unicode twins, the stooges. On the right i added a screenshot of what the lefthand text looks like over here. Arsen Mullagaliev reminded me of the fact, that on your local system the Stooges might look different (probably just like questionmarks).
This function will print the above to your debug window: Comment by Arsen Mullagaliev, 04-May-2002 On my system AscW(Chr$(154)) returns 1113 (hex 0459) rather than 353. And it's not really surprising: VB strings are encoded in 16-bit Unicode (UCS-2), and so VB has to transform ANSI character \154 to Unicode, using the default code page of the system. In my case, it's the Cyrillic alphabet, while in your case it's probably Western European (I'm not sure). Asc(Chr$(154)) does the inverse transformation, Unicode to ANSI, which is why you get 154 as expected. AscW just returns the two-byte pair as a single number. |